|
Autonomous Racing
1
f1tenth Project Group of Technical University Dortmund, Germany
|
|
Autonomous Racing
1
f1tenth Project Group of Technical University Dortmund, Germany
|

Public Member Functions | |
| def | __init__ (self, policy, actions, laser_sample_count, max_episode_length, learn_rate) |
| def | on_crash (self, _) |
| def | get_episode_summary (self) |
| def | on_complete_episode (self) |
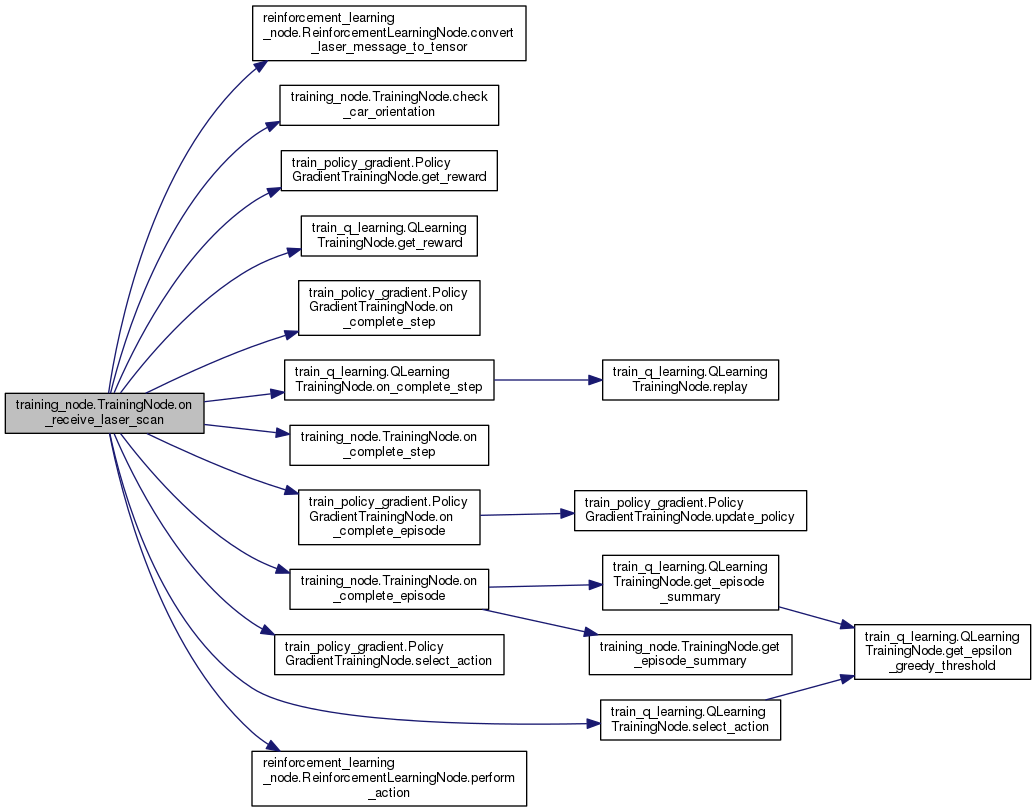
| def | on_receive_laser_scan (self, message) |
| def | on_complete_step (self, state, action, reward, next_state) |
| def | check_car_orientation (self) |
| def | on_model_state_callback (self, message) |
 Public Member Functions inherited from reinforcement_learning_node.ReinforcementLearningNode Public Member Functions inherited from reinforcement_learning_node.ReinforcementLearningNode | |
| def | __init__ (self, actions, laser_sample_count) |
| def | perform_action (self, action_index) |
| def | convert_laser_message_to_tensor (self, message, use_device=True) |
| def | on_receive_laser_scan (self, message) |
Abstract class for all methods that are common between Q-Learning training and Policy Gradient training
Definition at line 21 of file training_node.py.
| def training_node.TrainingNode.__init__ | ( | self, | |
| policy, | |||
| actions, | |||
| laser_sample_count, | |||
| max_episode_length, | |||
| learn_rate | |||
| ) |
Definition at line 32 of file training_node.py.
| def training_node.TrainingNode.check_car_orientation | ( | self | ) |
| def training_node.TrainingNode.get_episode_summary | ( | self | ) |
| def training_node.TrainingNode.on_complete_episode | ( | self | ) |
Definition at line 92 of file training_node.py.


| def training_node.TrainingNode.on_complete_step | ( | self, | |
| state, | |||
| action, | |||
| reward, | |||
| next_state | |||
| ) |
| def training_node.TrainingNode.on_crash | ( | self, | |
| _ | |||
| ) |
Definition at line 69 of file training_node.py.
| def training_node.TrainingNode.on_model_state_callback | ( | self, | |
| message | |||
| ) |
Definition at line 154 of file training_node.py.
| def training_node.TrainingNode.on_receive_laser_scan | ( | self, | |
| message | |||
| ) |
| training_node.TrainingNode.action |
Definition at line 49 of file training_node.py.
| training_node.TrainingNode.car_orientation |
Definition at line 51 of file training_node.py.
| training_node.TrainingNode.car_position |
Definition at line 50 of file training_node.py.
| training_node.TrainingNode.cumulative_reward |
Definition at line 41 of file training_node.py.
| training_node.TrainingNode.cumulative_reward_history |
Definition at line 46 of file training_node.py.
| training_node.TrainingNode.drive_forward |
Definition at line 53 of file training_node.py.
| training_node.TrainingNode.episode_count |
Definition at line 38 of file training_node.py.
| training_node.TrainingNode.episode_length |
Definition at line 39 of file training_node.py.
| training_node.TrainingNode.episode_length_history |
Definition at line 45 of file training_node.py.
| training_node.TrainingNode.episode_result_publisher |
Definition at line 66 of file training_node.py.
| training_node.TrainingNode.episode_start_time_real |
Definition at line 56 of file training_node.py.
| training_node.TrainingNode.episode_start_time_sim |
Definition at line 57 of file training_node.py.
| training_node.TrainingNode.is_terminal_step |
Definition at line 42 of file training_node.py.
| training_node.TrainingNode.max_episode_length |
Definition at line 36 of file training_node.py.
| training_node.TrainingNode.net_output_debug_string |
Definition at line 44 of file training_node.py.
| training_node.TrainingNode.optimizer |
Definition at line 59 of file training_node.py.
| training_node.TrainingNode.policy |
Definition at line 35 of file training_node.py.
| training_node.TrainingNode.state |
Definition at line 48 of file training_node.py.
| training_node.TrainingNode.steps_with_wrong_orientation |
Definition at line 54 of file training_node.py.
| training_node.TrainingNode.total_step_count |
Definition at line 40 of file training_node.py.
 1.8.11
1.8.11